En las ciencias de la computación, de acuerdo con Lamport (1979), un
hilo de ejecución corresponde a la más pequeña secuencia de
instrucciones programadas que pueden ser administradas de forma
independiente por el programador, parte del sistema operativo.
La implementación de los hilos y procesos es diferente en los sistemas
operativos. En su libro Moden Operating Systems, Tanenbaum (1992)
muestra que muchos modelos de organización de procesos son posibles. En
muchos casos, un hilo es un componente de un proceso. Los múltiples hilos
asignados a un proceso pueden ser ejecutados de forma
concurrente (multithreading), compartiendo recursos como
la memoria, mientras que diferentes procesos no comparten estos
recursos.
En particular, los hilos de un proceso comparten su
código ejecutable, y los valores de sus variables asignadas de forma dinámica y las variables globales, que no son locales para
cada hilo, en cualquier momento.
Los hilos aparecen bajo el nombre de tareas (tasks) en el sistema operativo OS/360 con de la implementación de la
Multiprogramación con número Variable de Tareas (MVT) en 1967. Saltzer (1966) nombra a Victor A. Vyssotsky como el pionero del
término "hilo" (thread).
El uso de hilos en aplicaciones de software se hizo más común durante la
primera mitad de los 2000s a medida que las CPU empezaron a utilizar más
núcleos(cores). Las aplicaciones deseaban
aprovechar los múltiples núcleos por las ventajas de rendimiento que
se necesitaban para emplear la concurrencia al utilizarlos.
¿Qué es la concurrencia?
Concurrencia es la habilidad de diferentes partes o unidades de un
programa, algoritmo o problema para ser ejecutadas fuera de orden, o en orden parcial, sin afectar la salida/resultado del mismo. Esto permite la ejecución en paralelo de unidades concurrentes, que puede aumentar significativamente la velocidad de ejecución en
sistemas multi-procesador y multi-núcleo.
Lamport (1978) indica que la concurrencia, en un sentido más técnico, se
refiere a la descomponibilidad
de un programa, algoritmo, o problema en componentes/unidades de cómputo de orden independiente o parcial.
Hilos del Kernel
Un hilo de kernel es una unidad de poco peso de
programación de kernel (kernel scheduling). Al menos un hilo
de kernel existe por cada proceso. Si existen múltiples hilos dentro de un
proceso, estos comparten los mismos recursos de memoria y archivos.
Estos hilos no son dueños de recursos, además de un una
pila (stack), una copia de los registros incluyendo el
contador del programa, y el almacenamiento local del hilo,
disminuyendo su coste de creación y destrucción.
De acuerdo a la documentación de IBM (2023), un hilo de kernel se define
como la
entidad programable, manejada por el programador del sistema
(system scheduler). Son fuertemente dependientes de su
implementación, por lo que, para facilitar el desarrollo de programas
portables, las librerías proveen hilos de usuario.
Hilos de Usuario
En ocasiones, los hilos son
implementados en librerías del espacio de usuario (userspace). El kernel no está consciente de estos, por lo que son programados y
administrados en el espacio de usuario. Algunas implementaciones
basan sus hilos de usuario encima de múltiples hilos de kernel, para
beneficiarse de las máquinas multi-procesadoras. Estos hilos son implementados por las máquinas virutales, donde
también se les denomina hilos verdes (green threads).
El
cambio de contexto entre los hilos de usuario de un mismo proceso
es extremadamente eficiente porque no requiere de ninguna interacción
con el Kernel en absoluto. El cambio de contexto puede ser realizado mediante el guardado local de
los registros de CPU usados por hilo de usuario en ejecución y después
cargando los requeridos por el usuario para ser ejecutados.
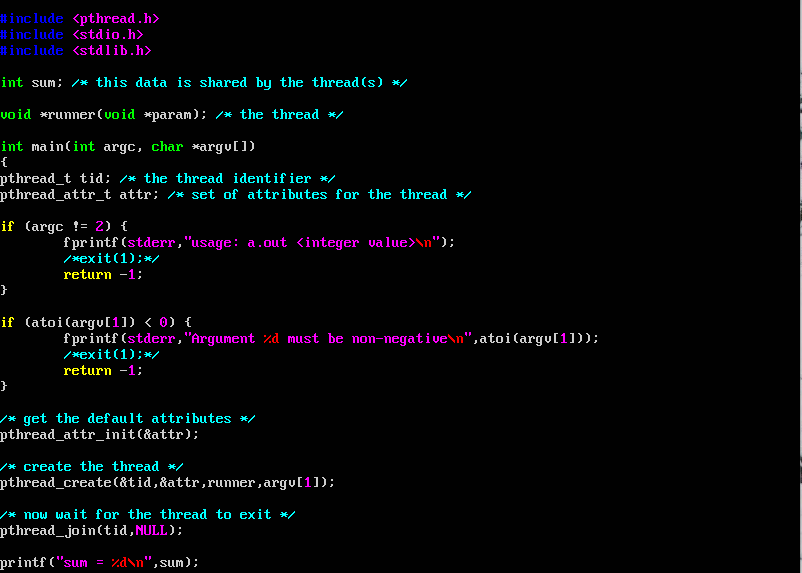
En la imagen anterior podemos ver la ejecución de una prueba de concepto
de un chat desde la terminal, que implementa hilos y listeners para la
ejecución concurrente desde 2 clientes diferentes y un servidor.
A continuación el código fuente de un programa corto, escrito en lenguaje C
para identificar cómo funcionan los hilos desde su creación, hasta su
integración con el hilo de ejecución principal de un programa.
#include "stdio.h" // Librería estándar
#include "pthread.h" // Librería para manipulación de hilos
// Prototipo de función para ejecutar en cada hilo
void *computation(void *add);
// Función principal
int main(void)
{
// Declaración del hilo
pthread_t thread1;
pthread_t thread2;
long value1 = 1;
long value2 = 2;
// Llamado individual de cada función
computation((void *) &value1);
computation((void *) &value2);
// Creación del hilo y join al finalizar su ejecución
pthread_create(&thread1, NULL, computation, (void *) &value1);
pthread_join(thread1, NULL);
pthread_create(&thread2, NULL, computation, (void *) &value2);
pthread_join(thread2, NULL);
// Creación de ambos hilos y join al finalizar sus ejecuciones respectivas
pthread_create(&thread1, NULL, computation, (void *) &value1);
pthread_create(&thread2, NULL, computation, (void *) &value2);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}
// Función que retorna un puntero a void, en este caso NULL
void *computation(void *add)
{
long sum = 0;
long *add_num = (long *) (add);
for (long i = 0; i < 1000000000; ++i) {
sum += *add_num;
}
return NULL;
}
Ahora miremos cómo nos vemos beneficiados si entendemos cómo implementar correctamente el uso de hilos dentro de nuestro código:
1er caso: Llamado secuencial de la función computation()
Ubicamos dentro de comentarios los demás casos. Nuestra función principal debería lucir así.
Ahora miremos el tiempo que tardó en ejecutarse nuestro primer caso:
Un total de 3.738s.
2do caso: Creación de un hilo y llamado de su pthread_join() respectivo de forma secuencial con cada hilo
Ubicamos dentro de comentarios los demás casos. Nuestra función principal debería lucir así.
Ahora miremos el tiempo que tardó en ejecutarse nuestro segundo caso:
Un total de 3.748s
3er caso: Creación de cada hilo y llamado de sus pthread_join() respectivos tras finalizar la ejecución de ambos
Ubicamos dentro de comentarios los demás casos. Nuestra función principal debería lucir así.
Ahora miremos el tiempo que tardó en ejecutarse nuestro segundo caso:
Un total de 1.904s
Como podemos notar en el último caso, ambos hilos creados están cubriendo la ejecución de la función computation() de forma concurrente y no secuencial, para luego unirse al hilo principal de ejecución. Esto nos permitió reducir en, aproximadamente, la mitad del tiempo de ejecución necesario para un bucle for de mil millones de iteraciones por llamado.
Bibliografía consultada para la escritura de este post:
- Lamport, L. (Septiembre de 1979). "How to Make a Multiprocessor Computer That Correctly Executes
Multiprocess Programs". IEEE Transactions on Computers. C-28 (9): 690–691.
doi:10.1109/tc.1979.1675439
- Tanenbaum, A. (1992). "Modern Operating Systems".
Prentice-Hall International Editions. ISBN 0-13-595752-4.
- Saltzer, J. (Julio de 1966). "Traffic Control in a Multiplexed Computer System" Tesis de Doctorado en Ciencias. p.20.
- Lamport, L. (Julio de 1978). "Time, Clocks, and the Ordering of Events in a Distributed System". Communications of the ACM. 21 (7): 558–565.
doi:10.1145/359545.359563.
- IBM Documentation. (20 de enero de 2023). "Kernel Threads and User Threads". IBM. https://www.ibm.com/docs/da/aix/7.2?topic=processes-kernel-threads-user-threads
- Portfolio Courses. (25 de febrero de 2023). "Introduction To Threads (pthreads) | C Programming Tutorial". Portfolio Courses. https://www.youtube.com/watch?v=ldJ8WGZVXZk












Comentarios
Publicar un comentario